
Translation memory (TM) is a powerful tool for producing high quality automatic translations. It does so in two ways:
The benefits of translation memory
First, whenever an automatic translation is reviewed by a human (and marked “All lines reviewed” in the document editor) it will save the source sentence and translation as an entry in the memory. When that source line is encountered in the future, spf.io will use the approved human translation, giving you great confidence in the translations your audience receives.
Second, when you have a large enough translation memory, it can be used to adapt machine translation so that automatic translation of new phrases and sentences fits better with your domain and translation preferences. That’s right, the system can get smarter and start imitating what your translators prefer!
Having a human translator in the loop (reviewing automatic translations and saving them to the translation memory) creates a virtuous cycle so that over time the automatic translations spf.io produces for your content get more finely tuned to your preferences. This means less work for human reviewers in the future and better translations for your audiences even when you when you aren’t able to get translation reviewed ahead of time!
Spf.io’s new tools for analyzing translation memory quality
In the latest release of spf.io, we’ve added new tools that help you monitor the quality or health of your translation memory. These ensure you get the most benefit out of it and don’t accidentally mess up translations with misaligned, incorrect or unusable text. As the saying goes, “garbage in, garbage out”…let’s help you take out the garbage!
To access them go to Settings > Translator and click on the Translation Memory tab.
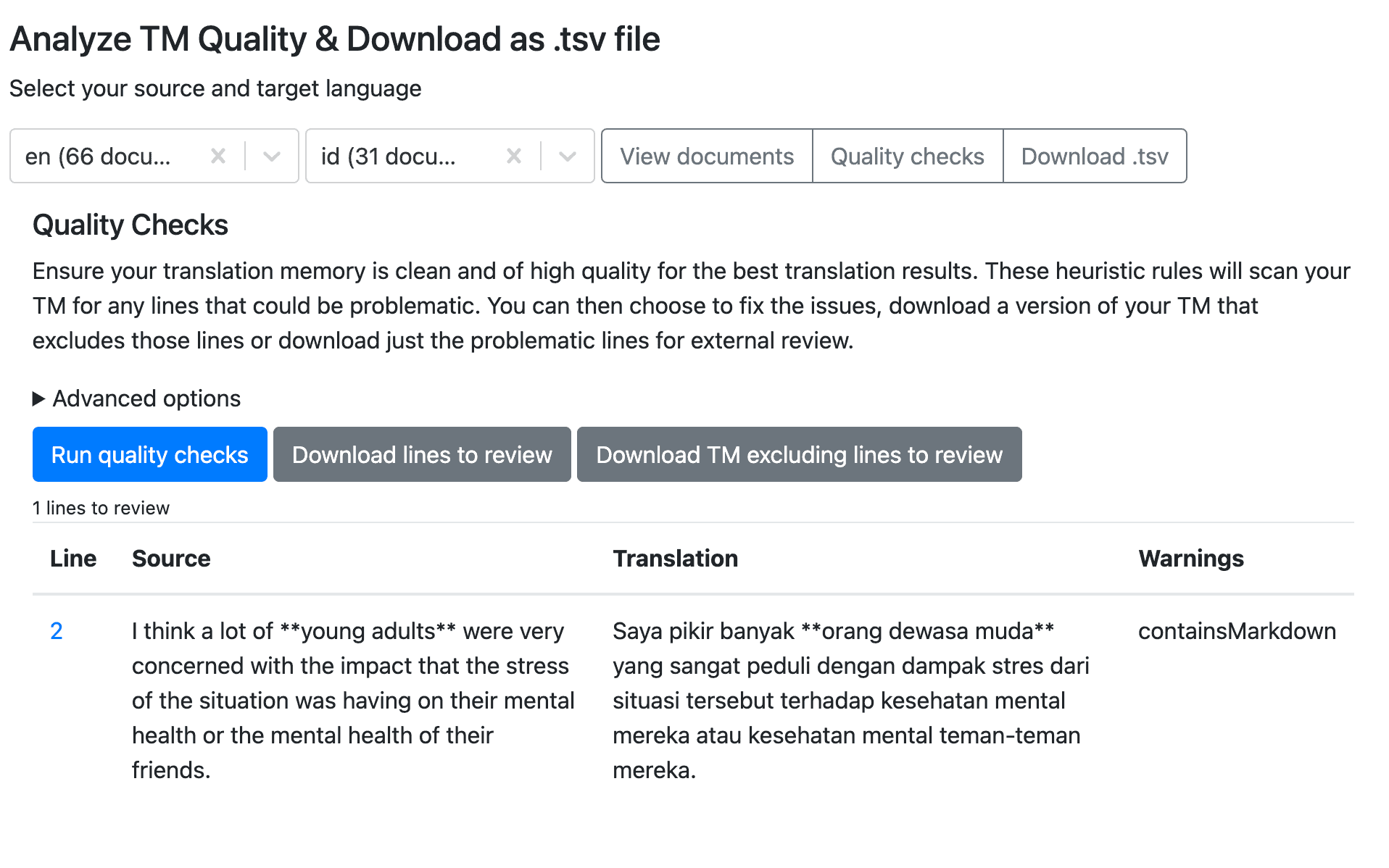
In the analysis tool, you simply select the source and target language and spf.io will scan all the human reviewed documents in your instance to find any potentially problematic lines. It uses different rules like searching for formatting markup (e.g. web links, markdown, html), and comparing the length of the source and translation sentences. The results are shown in a table or you can download them as a tab separated values (.tsv) file.
Every language pair is of course unique. For example English may be about 3 times the number of characters as Chinese, but 3/4 the number of characters as Indonesian. Spf.io provides advanced options so you can configure the rules to find potentially problematic lines for whatever language pair you are working with.
Quick links to the documents where these lines are found make it easy to fix many warnings that come up through the analysis.
We’re excited to add these powerful tools to your kit and hope they help you keep your translation memory in tip top shape!
PS, when your TM reaches more than 10,000 human reviewed lines for a particular language pair, that’s a great time to consider creating an adapted machine translation model. Contact us if this is something you would like to try!